

参考链接: https://mp.weixin.qq.com/s/6ioR3JE0wKg6M-YAsLBcTA
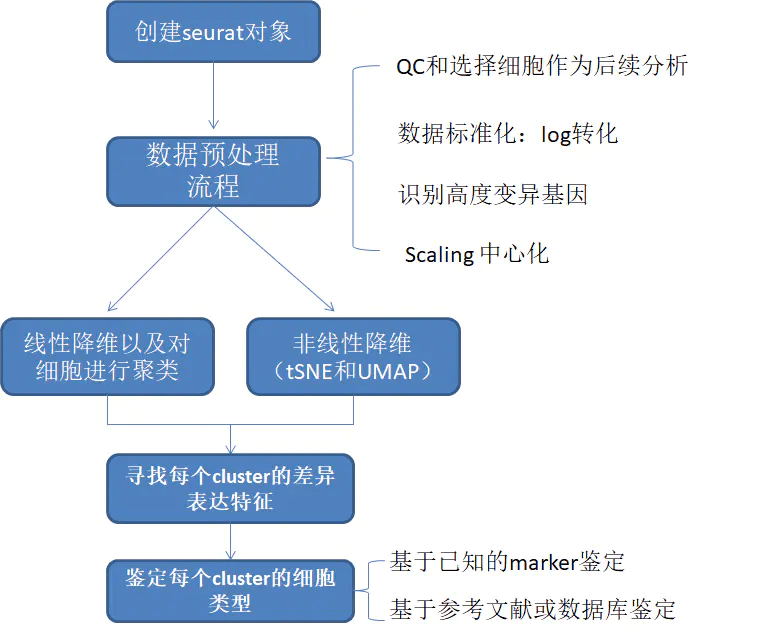
关于归一化和标准化的翻译看了很多中文资料,发现还是有争议的,在seurat中主要是两个函数:NormalizeData()和ScaleData() ,其实可以泛称为“标准化”
Normalization:"normalizes" within the cell for the difference in sequenicng depth / mRNA throughput. 主要着眼于样本的文库大小差异
Scaling:"normalizes" across the sample for differences in range of variation of expression of genes . 主要着眼于基因的表达分布差异
归一化
NormalizeData() (默认使用LogNormalize方法)暂且将其称为“归一化”
归一化 “归”的是文库大小。让同一基因的表达量在不同样本之间具有可比性。
LogNormalize: normalizes the feature expression measurements for each cell by the total expression, multiplies this by a scale factor (10,000 by default), and log-transforms the result. 公式写作:log1p(value/colSums[cell-idx] *scale_factor)
log1p()是e为底(1+x)的对数
不同细胞的起始底物浓度不同,导致cDNA捕获或PCR扩增效率差异。归一化的目的就是去除细胞间与真实表达量无关的技术因素,方便后续比较
至于为什么取log? 就是为了不受真实值的影响,而关注变化倍数。这里举个例子,X基因在细胞A的表达量是50,在B细胞的表达量是10;而Y基因在细胞A的表达量是1000,在B细胞的表达量是1100。哪个基因更能吸引你的注意呢?我们是不是会关注变化的倍数?
原始表达量是一个离散程度很高的值,有的高表达基因表达量可能成千上万,可有的却只有几十。即使采用了一些归一化的算法消除了一些技术性误差,但真实存在的表达量极差往往会影响之后绘制热图、箱线图的美观性,于是可以另外采用log 进行一个区间缩放(却不会影响真实值),比如原来表达量为1的,用log2(1+1)转换后结果依然为1;原来表达量为1000的,log2(1000+1)转换后约为10。那么原来相差1000倍的变化,现在只差10倍,在不破坏原有数据差异的同时,使数据更加集中。
另外,既然要取log,就应该要注意存在很多0表达量的数值,因此log前还需要给表达量加上1,log1p = log(x + 1),这个1就称作:pseudocount(伪计数,归一化的同时实际上引入了误差)。
据说SCTransform方法可以规避这个问题,实现更可靠的归一化,有待学习
标准化
ScaleData() 对数据进行线性转换 暂且称为“标准化”,降维处理(如PCA)之前的标准预处理
之前归一化(normalize)做的操作是log处理,它是对所有基因的表达量统一对待的,最后放在了一个起跑线上。但是为了真正找到差异,我们还要基于这个起跑线,考虑不同样本对表达量的影响
Scales and centers features in the dataset. If variables are provided in vars.to.regress, they are individually regressed against each feature, and the resulting residuals are then scaled and centered.
从帮助文档中可以看出,ScaleData()实际上是对数据进行了scale和center两个步骤
对数据进行标准化后:
- 使每个基因在所有细胞的表达量均值为 0
- 使每个基因在所有细胞中的表达量方差为 1
标准化的目的是为了避免那些表达很高的基因的变化,掩盖了表达丰富较低但也有意义的基因,所以把这些基因缩放在合适的范围,以便能看到所有有意义基因的差异。
ScaleData这个函数有两个默认参数:do.scale = TRUE和do.center = TRUE,然后需要输入进行scale/center的基因名(默认是取标准分析流程中上一步FindVariableFeatures的结果)。
center就是对每个基因在不同细胞的表达量都减去均值;scale就是对每个进行center后的值再除以标准差


暂无评论内容